Exploitation of HTML mark-up in information extraction from small business websites is usually considered unfeasible due to illogical use of tags by web designers. We hypothesize that some semantic content could be obtained even from pages whose creation was merely constrained by the outlook. The suggested approach consists in decomposition of the mapping between the HTML source patterns and semantic messages into three layers, including visual patterns as well as a simple generic structure: the subject-predicate-object triple known from RDF. We outline a formal framework for our approach and show results of a small empirical study dealing with contact information on business sites. In the future, the method could focus information extraction procedures on promising parts of the HTML code. Further, having its basis in triples, it could act as support for interactive semantic (RDF) annotation.
Information Extraction, RDF
The discipline of Web Information Extraction (WebIE) encompasses techniques directly adopted from plain-text Information Extraction (IE) as well as those introduced by web structures. The first group covers string matching, linguistic parsing and statistical modelling (e.g. Hidden Markov Models). The second group explicitly accounts for mark-up: either in the form of wrappers enabling online querying to large, database-like pages, with stress on regular mark-up patterns [2, 3], or by means of hybrid approaches combining text, symbols, mark-up and possibly hyperlinks in a powerful representation, usually for offline template-filling based on loosely structured (e.g. university department or advertisement [1, 5]) pages. The majority of small business websites is however considered as outside the scope of HTML-aware techniques. The often-mentioned reason is that 'occasional web designers' ignore all kind of standards and conventions, and their use of HTML tags is completely haphazard. An extraction model developed for one site will thus fail on other sites, while building models always from scratch is unaffordable given the small size of the sites. Extraction of knowledge 'buried' under this 'mess of tags' may be, though, valuable in large scale - e.g. for linking the sites to the Semantic Web, since few among their webmasters will have time and capability to take care of semantic annotations by themselves.
In this paper, we are striving for a novel method capable of distilling at least some semantic content from ill-structured pages. The key ideas are: to decompose the mapping between HTML source code and 'semantic messages' into multiple parts, and to employ a generic data model - the (RDF-like) SPO triple.
Since the choice of HTML tags is always constrained by the outlook in the browser, we propose to model the outlook (in terms of 'visual' relations and properties such as 'above', 'tabular-left-to', 'emphasized' or 'indented') as an intermediate layer between the HTML source code and the semantic model. Though the separated mappings are still n-to-m, the n, m are likely to be smaller than if the HTML structures were directly matched with 'semantic messages' (earlier we empirically identified common 'messages' on business sites, such as company profiles, contact info or catalogues). To further reduce complexity, we identified a %decided to treat various 'semantic messages' in terms of one or a few generic 'message schemes'. It eventually turned out that a single, very simple model applicable on the majority of messages: the subject-predicate-object (SPO) triple. It expresses that ''the value (i.e. object) of property (i.e. predicate) X for entity (i.e. subject) Y is Z''. The wide usability of this structure seems to be endorsed by its adoption for the Resource Description Framework (RDF) [4].
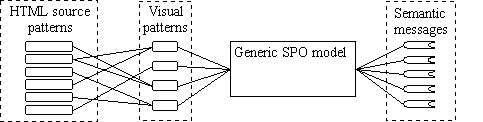
Figure 1: Multi-layer mapping
The leftmost part of Fig.1, relating HTML source patterns to visual patterns, represents by itself a hard problem we do not address here. The middle part maps visual patterns to the SPO triple: the object part of HTML code is likely to 'follow' (in a varying visually-topological sense) the predicate part, e.g.:
The subject is usually not referenced in HTML code; typically, it is the company itself or one of its products/services, which can be expressed in RDF e.g. by means of an anonymous resource:
<rdf:Description about="http://www.XY.com"> <dc:References rdf:resource="_anon1" a:Email="info@XY.com" /> </rdf:Description> <rdf:Description about="http://www.XY.com/catalog#item3"> <dc:References rdf:resource="_anon2" a:Price="800" /> </rdf:Description>
The rightmost part of diagram, relating the generic model to specific messages, is treated in more detail in the following section.
The generic SPO model is reflected in the structure of SPO extractor (SPOE), the universal model we propose for detection and extraction of specific types of semantic messages:
An SPO extractor is a tuple (S,P,O,V), where
- S (the subject specification) is a logical expression.
- P (the predicate specification) is a pair (Pred,Lex), where Pred is a semantic predicate and Lex either a lexical pattern or 'nil'.
- O (the object specification) is an information extractor.
- V specifies the subset of visual patterns applicable on the given extraction task. (A single library of visual patterns could be reused by different SPO extractors.)
Indicative lexical patterns are understood as clue for identifying the HTML code corresponding to P; they may however be left out - e.g. an address at a company homepage could be considered as 'contact address' even without preceding pattern such as 'Contact:'. Semantic predicates should be defined as ontological properties, i.e. valid RDF resources. The nature of information extractors may vary from e.g. identity function ('pick up the whole content of element') to complex linguistic or statistical models. The logical expression specifying the subject could be just a default value such as 'current page' or 'website homepage', or could return different values depending e.g. on the semantic class of current page. (Diverse ways of page classification, e.g. URL-, HTML- or topology-based, are addressed by the Rainbow architecture (http://rainbow.vse.cz), in which the method will be tested.
A simple algorithm for discovery of 'implicit RDF statements' for semantic predicate Pred in a given HTML page Pg may, for example, look like this (looping omitted for brevity):
Small 'predicate-object' patterns also could be embedded in the code of the 'object' part of a larger pattern: e.g. 'price' in a 'catalog' or 'e-mail' in 'contact info'. This could be modelled by meta-predicates, and exploited by a more complex, recursive algorithm.
In the first try we focused on contact information data, i.e. postal and/or email address, see Table 1. We randomly selected 101 links from the Business category of Open Directory (http://dmoz.org/Business), and visually examined the HTML code and outlook of the respective websites. We found some form of contact information within 60 sites: either at the main page or at a page accessible via an appropriately labelled link (such as 'Contact us' or 'About us').
| Extractable address | 50 | 83 % |
| - using lexical indicators (SPOE) | 21 | 35 % |
| - only using advanced methods | 29 | 48 % |
| Non-extractable address | 4 | 7 % |
| Contact info w/o address | 6 | 10 % |
| Extractable email: | 38 | 63 % |
| - using a simple 'mailto:' wrapper: | 31 | 52 % |
| - using lexical indicators (SPOE): | 27 | 45 % |
| - only using lexical indicators (SPOE): | 7 | 11 % |
| Contact info w/o email | 22 | 37 % |
| Any metadata present | 29 | 48 % |
| Metadata with contact info present | 4 | 7 % |
Table 1: Results for the 60 sites with contact info available
For all occurrences of address, we assigned the possibility of their automatic extraction to one of the categories:
The simplest approach to e-mail extraction would surely be a wrapper class for <a href="mailto:XXX">: this would work in approx. 50 % of cases.
When, however, the address does not have the form of hyperlink and its end coincides with that of an appropriate HTML tag,
an SPO extractor (using lexical indicators such as 'E-mail:') still would work (11 % of cases).
A by-product of our survey was a small statistics of use of explicit metadata. Some form of it occurred on nearly half of the pages, structured metadata (Dublin Core) however appeared just once, and only 4 pages contained metadata with contact information: this manifests the importance of WebIE. For contact information, 'implicit RDF metadata' on output might look like
<rdf:Description about="http://www.XY.com"> <dc:Creator>Joe Bowen</dc:Creator> <imp:email>info@XY.com</imp:email> <imp:addr>42 StreetX, Bigcity, 111 54</imp:addr> <imp:phone>1-800-123-456</imp:phone> </rdf:Description>
and later be converted to 'real-world' facts, as shown in section 2.